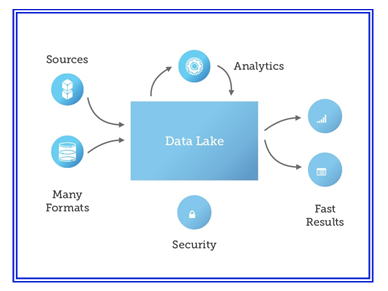
Data Lake is a new storage concept that is gaining ground in the Cloud. Often the Data Lake term is being used as part of the Big Data solution. In theory, it is where you can store raw data in its native format, usually in Hadoop and Hadoop Distributed File System (HDFS). It can be used and processed to create data sets for other applications and users as and when needed. You don’t worry about the complex (and often expensive) data pipeline needed to simply collect and store diverse data.
The credit for coining the term Data Lake goes to James Dixon, Pentaho Chief Technology Officer. Dixon used the term initially to contrast with “data mart”, which is a smaller repository of interesting attributes extracted from the raw data.
Currently, Hadoop is the most common technology to implement a Data Lake, but new players are entering this field. A Data Lake is a concept while Hadoop is a technology to implement the concept.
It is compatible with the Hadoop File System and will work with most of the standard Hadoop big data tools like Spark, Storm and Kafka, as well as services from Hortonworks, Cloudera and Microsoft’s Azure HDInsight.
Big Data and Data Lake get close
The world of Big Data is expanding with data being generated every second from multiple communication channels. Consequently, Data Lake solves the need to store this unstructured and unorganized data. You can consider Data Lake as a parallel system able to store big data, and a system to perform computations on the data without moving the data.
Often Data Lake is confused with Data warehouses. The primary difference between them is that the Data Lake stores data in its native format. Big Data uses this unspecified data to uncover valuable insights on how the data is being used, and how to use this to their advantage. This is difficult for data analysts when the data is pre-organized in specific formats as seen in the data warehouses.

With the Internet of Things, being next big wave, it’s natural for Data Lake to gain more importance. The absence of any rigid format structures, is its plus point. But, it also limits on how the data is being accessed and used.
Since the data is not defined, you have no idea about what exactly is being dumped into a lake. Until you start searching and analyzing the data, you will not know if it’s useful. The lack of any unique identifiers, meta descriptions about the data, category or class designations, will make it difficult to access your exact data for analysis.
Another thing to worry about is the security of the data being dumped into the lake. As with all new concepts, organizations should push for better security measures, before entirely dumping their data into the lake. Plus, data corruption may also occur if it is left unused for long.
Andrew White, VP of Gartner writes: “The need for increased agility and accessibility for data analysis is the primary driver for Data Lakes. Nevertheless, while it is certainly true that Data Lakes can provide value to various parts of the organization, the proposition of enterprise-wide data management has yet to be realized.”
Data Lake will continue to be popular with Big Data and Internet of Things streaming data from various connected devices. The still emerging concept will need further maturity, security and organization, before it will be embraced completely by businesses.
Sysfore can help you store data using the Big Data and Cloud. You can contact us at info@sysfore.com or call us at +91-80-4110-5555 for more information.